
iZotope research team
We drive the algorithmic vision for iZotope products
Through scientific leadership and innovation in digital signal processing, iZotope's industry-leading research team has contributed meaningful developments to the industry at large, and the iZotope products you know and love. Learn more about the team, and opportunities to join, below.
Meet the team

Alexey Lukin
Alexey is iZotope’s Principal DSP Engineer. He earned his M.S. (2003) and Ph.D. (2006) in computer science from Lomonosov Moscow State University, Russia. He specializes in audio signal processing, with particular interest in crossovers with image processing in spectral analysis, noise reduction, and multiresolution filter banks. Alexey’s published work includes over 30 papers and 8 patents. He has been acknowledged with an Academy of Motion Picture Arts and Sciences' Scientific and Engineering Award for the development of iZotope RX—the audio repair toolkit.

Andy Sarroff
Andy Sarroff is a Research Engineer at iZotope. He received an MM in Music Technology from New York University and a PhD in Computer Science from Dartmouth College with a dissertation on “Complex Neural Networks for Audio.” He has been a visiting researcher in the Speech & Audio group at Mitsubishi Electric Research Laboratories (MERL), as well as Columbia University’s Laboratory for the Recognition and Organization of Speech and Audio (LabROSA). Andy has served on the board of the International Society for Music Information retrieval and is currently a Chair of the Audio Engineering Society’s Technical Committee on Machine Learning and Artificial Intelligence for Audio (TC-MLAI).
Research Highlights
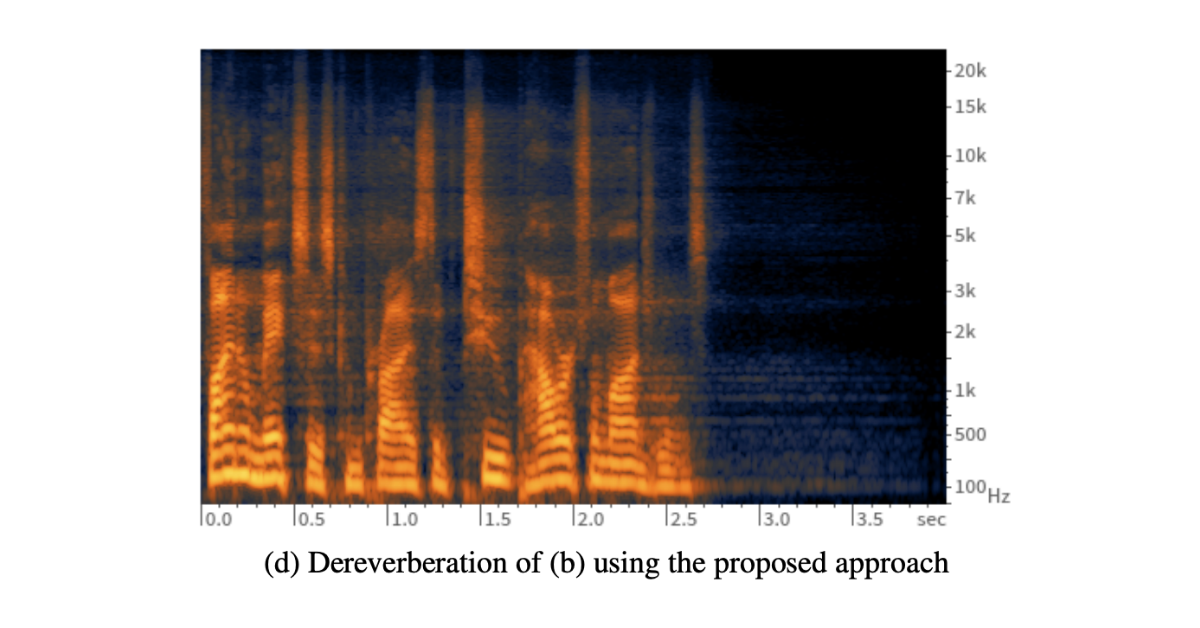
Speech Dereverberation using Recurrent Neural Networks
In this paper, we show how a simple reformulation allows us to adapt blind source separation techniques to the problem of speech dereverberation and, accordingly, train a bidirectional recurrent neural network (BRNN) for this task.
Shahan Nercessian and Alexey Lukin
Energy-Preserving Time-Varying Schroeder Allpass Filters and Multichannel Extensions
We propose time-varying Schroeder allpass filters and Gerzon allpass reverberators that remain energy preserving irrespective of arbitrary variation of their allpass gains or feed- back matrices over time.
Kurt James Werner, François G. Germain, and Cory S. Goldsmith
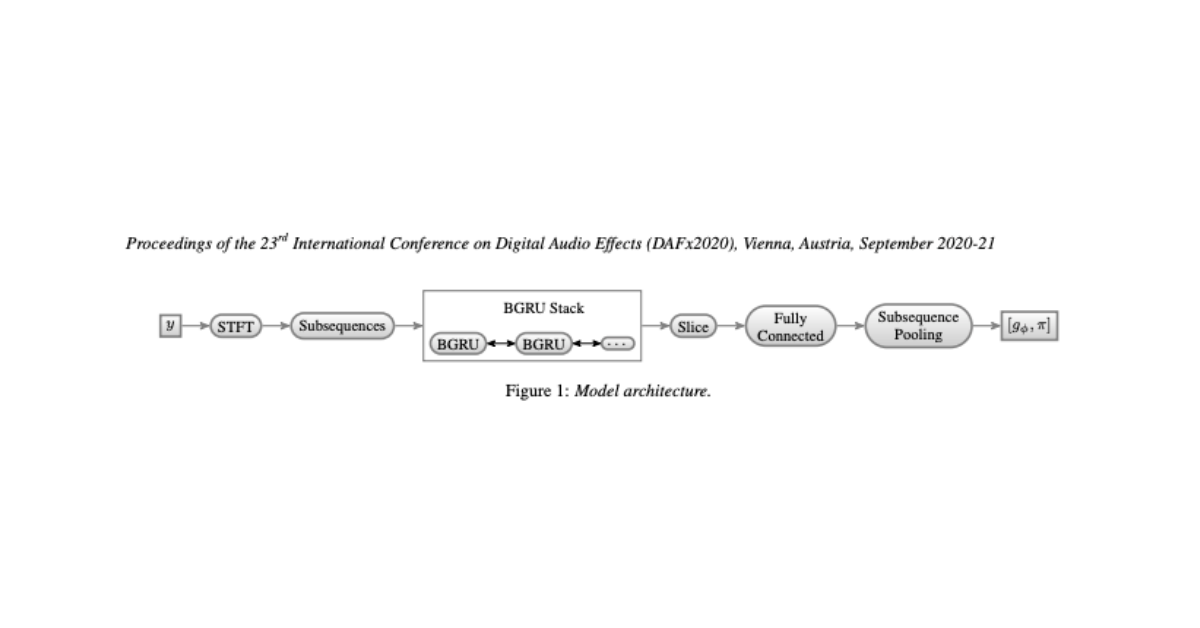
Blind Arbitrary Reverb Matching
We propose a model architecture for performing reverb matching and provide subjective experimental results suggesting that the reverb matching model can perform as well as a human.
Andy Sarroff and Roth Michaels
Research Team Articles

Audio Research Internship Program
Our Audio Research Interns help explore new technologies under the mentorship of a relevant research team-member. This is a 3–4 month program.